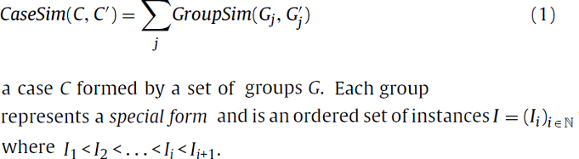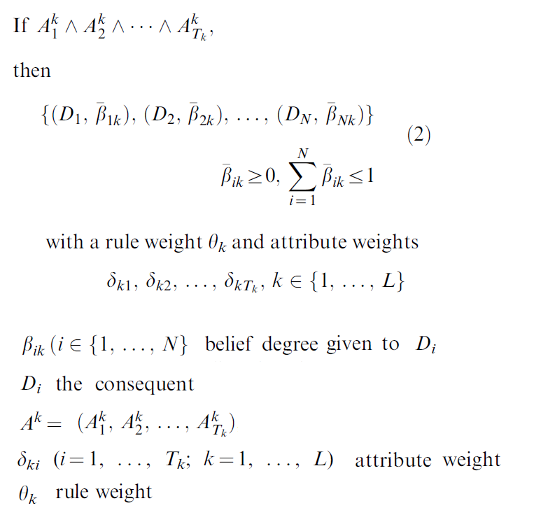What is cool about it? Drag and drop EMRs lets non-programming doctors and nurses customize their own EMR user interface. They call their system "MedWISE."
Summary
Look at this drag-and-drop EMR!
13 physicians tried it out in a think loud process. and said what they liked and did not like about it.
Clues
1. Doctors know what more about medicine and workflows that programmers
1. New made up theory: intelligent uses of space - "the EHR should fit to the doctor or nurse's way of thinking, not the other way around."
2. New made up word: produsage, portmanteau of producer and user. They can share stuff with their colleagues -- ehhh, well, why not?
2. There were three different schools of thought on organizing the page: structured, dynamic, and opportunistic. Not really sure what the difference is, but basically the doctor organized the page in a way that made sense to him. Note: doctors changed their school of thought if the patient case called for it.
3. New made up word: metadesign, lets the user determine software features in real life --- pretty cool
3. Having clinicians choose to keep the relevant information and discard the erroneous or outdated information means this interface is more relevant than the usual system
4. Stop all the sequential views. Better to keep everything on one screen so people do not have to remember what was on the last screen and the one before that. Also cool, but everyone will need huge monitors. More money for monitors!
Quotes
In our experience, the code base and amount of programming required to create a flexible composable system may be smaller than that required to accommodate each individual need and context ad hoc -- doh ho ho ho
"... having one page to [drag and drop information on a screen] ... made me question what's really important. There's only so much screen real estate and it's all really valuable ... I really like having a one-page summary" - a physician user "You can see at large it's all based on having being processed by a clinician. That's what we like to focus [on]." - a physician user
Basic information about clinical decision support systems (CDSS)
Summary
There are 10 grand challenges if we want to achieve the ultimate goal of clinical decision support (CDS) -- personalize medicine using all of the complex data available.
"Half of what we now know about medicine is incorrect, but unfortunately do not know which half." - Sir William Osler, 1910
Grand challenges
Improve the human-computer interface - CDS recommendations should remind physicians of things they have overlooked, but do this seamlessly into the workflow. Not unsolicited alerts that people override.
Diagnosis of a disease is complicated and can be done over time. Sometimes you have to try different medications on patients to see if the patient responds, or wait for lab results. What is worse - physicians have imperfect self-knowledge of their own diagnostic problem solving capabilities.
Summarize patient-level information - automatically summarize all the electronic patient data, both freetext and coded, into one page. This allows "at-a-glance" assessment of patient status.
CDSS fall under 3 categories:
Find the correct diagnosis from hundreds of possible orders - use patient findings as input and produce differential diagnosis and recommendations as output.
Focused diagnosis - choose a diagnosis from a limited sub-speciality, such as ECG readings
Focused image interpreter - detecting diseases in various images such as pathology slides or digitized x-rays
This article only talks about the first one.
Filter recommendations to the user - The system should prioritize and filter alerts based on clinical factors such as mortality and morbidity reduction and patient preferences, but also to reduce the overall numbers so that we can avoid "alert fatigue."
Combine recommendations from conflicting guidelines - the CDS should synthesize guidelines that may be redundant, contraindicated, potentially discordant, or mutually exclusive. For example, a patient with diabetes may need a medication, but their CPOD and heart failure also has guidelines that recommends against that. We will need new combinatorial or logic to sort this one out.
1960 - Warner and colleagues at LDS Hospital in Salt Lake City made the first operational Bayesian CDSS to diagnosis congenital heart disease.
Very sensitive to false positives and errors in their own database
Pointed out the need for a "gold standard"
Use the freetext - At least 50% of the clinical information in EMRs is freetext. We need to extract it.
Other approaches to CDSS include:
Statistical clustering, which evolved to support vector machines
Branching logic
Quantitative physiological models, which evolved to multi-tiered explanatory models
test-selection - identifies the best test to order
pattern-sorting - determine which diagnoses are best
Prioritize CDS content development - Some interventions or content is more important to develop than others. We should prioritize based on value to patients, cost to the health care system, availability of data, difficulty of implementation, acceptability to clinicians, etc.
The evolution of heuristic CDSS include:
1976 - Present illness program (PIP)
1974 - Internist-1
1980 - Quick Medical Reference (QMR)
1986 - DXplain
1987 - Iliad
2004 - Isabel
Mine clinical databases - Mining these is important, but it is also important to give researchers access cross-institution and organization
1972 - 1983: Internist-1/Quick Medical Reference (QMR) - Jack Myers, Harry Pople, and Randolph Miller worked to make Internist-1. They made a knowledge base and computer algorithms to help diagnosis in internal medicine. The doctor would input the patient history, physical exam, lab data, and the program would output a diagnosis or a list of differential diagnoses. The kb comprised of academic, evidence-based literature, and maintained through testing using actual patient cases.
Knowledge base - the use of the biomedical literature as a "gold standard" was novel. Previously, the accepted model was to pair a computer scientist with a doctor and have the doctor debrief the programmer on rules. This was not reproduceable, as different experts would create different kbs. The literature method, even when used by different domain experts in different settings, reproduced the same diseases profiles.
Algorithm development - This was made by analyzing the logic Myer used as he "thought aloud"
Disseminate best practices in CDS design, development, and implementation - we need information from successful CDS to be available to others. We wil need both measurement tools to determine which CDSs are the best, but also taxonomies to describe the interventions and outcomes.
Lessons learned from Interist-1 and QMR
Develop the kb using the biomedical literature as a gold standard, the only scientifically reproducable method
Use feedback from actual patient case analyses to change the kb or algorithms
Only change the kb if the knowledge base changes, not just to improve performance in an individual case
A CDS can help inexact physicians make diagnoses, and can rival a capable human
Make sure a senior, truly expert clinician is associated with a clinical informatics project, especially someone who does not have to be concerned with earning a reputation
Create a "plug and play" architecture for sharing CDS modules - there should be a way for hospitals to "subscribe to" an external CDS service. This requires that CDS modules and interfaces be standardized so that they can be shared.
1984 - 2002: Quick Medical Reference (QMR) - developed for those who did not like the "Greek Oracle" Internist. Physicians did not need CDS because they forgot how to make diagnosis; they used it because one step of a multi-step diagnosis is puzzling, or he is not familiar with a very rare disorder. The goals of QMR were to use Internist to create a "diagnostic tool kit" that a clinician would consult for a minute. It would support the physician pilot rather than be a tour-de-force CDS for rare cases, and help the diagnosis of more common diseases. Novel things included
QMR knowledge acquisition tool (QMR-KAT) - developed by Nunzia and Dario Guise. Kb builders could enter audit trails for diseases, provide frequency/sensitivity measures, and a measure of merit for how reliable an article was
Could provide differential diagnosis from only a few key findings of a case, and include cost-effective work-up suggestions for clinicians
User had greater control over diagnostic consultation - could decided when to generate questions or designate that certain diagnosis would be used as the topmost diagnosis for generating competitors
Create internet-accessible repositories, like CPAN - people should be able to download CDS modules from a maintained repository, like people can download Perl or Python modules and import them into their programs. This way, hospitals will not have to reinvent the wheel all the time.
Lessons learned from QMR
"First principle" is that clinicians, not systems, make diagnoses
The most definitive way of testing a CDS is to solve problems that clinicians cannot solve on their own. The ability to solve "artificial" cases is not so insightful. The ultimate evaluation is whether the system performs better than the unaided user.
Measuring therapeutic benefit, ie, advancing clinician knowledge well enough to help establish the correct diagnosis.
Another method is to generate simulated patients. If the fake patients seem off to a real clinician, it probably means the kb is not very good.
Future work
Solve these challenges!
There is no centralized, high-quality repository of ready-to-use clinical diagnostic knowledge, either for humans or CDSSS consumption. This is shameful in the age of the Internet, Medline, Cochrane, and Google. The biomedical literature is a start, but has been likened to drinking from a fire hose.
The HITECH Act and Meaningful Use are giving out big bucks to hospitals that have a clinical decision support system. Are these systems any good? These three articles focus on Child Health Improvement through Computer Automation, CHICA, a modern clinical decision support system (CDSS).
Summary
The main outcome was whether the pediatric physician responded to a CHICA prompt or not.
Alert fatigue phenomenon confirmed
Highlighting things in yellow does not make doctors pay more attention to them
Clues
1. Inputs were not always entered. Physicians answered fewer questions as the questions became more complex. Like 70% of physicians answered if the child passed a developmental milestone, but 38% answered if the parent was suspected of being abusive. For patients, similarly, easy questions would be when they switched from breast milk to cow milk, and hard questions would be cholesterol level or whether their water was a municipal or well water.
1. Statistically, physicians were more like to respond to prompts for younger patients and more serious issues
1. "Why didn't doctors pay more attention to yellow alerts"? Is content more important? Yes, and yes.
2. Alert fatigue confirmed: Alerts at the upper right and top of the page were more likely to be addressed. If there was a list of alerts, ones at the bottom were the least likely to be addressed.
2. Explanation 1: Yellow highlights are not attention-getting enough
3. Physicians respond less if there are >6 alerts or if the alerts want to make a huge decision that they are not ready for, like asthma diagnosis
3. Physicians were less likely to respond to alerts if the patients were uninsured. Boo!
3. Explanation 2: Physicians disagree with the reminder
4. Physicians respond more if the content of the alert is more familiar than if the alert is about unfamiliar content
4. CHICA is a rule-based system based on Arden Syntax medical logic modules (MLMs). It ranks alerts based on a score.
4. Explanation 3: They do not care
Take away message
Alert acceptance: still the same after 40 years
Alert fatigue is real: get your important alerts in first
Retrieve - retrieve cases that relevant to solving a target case. A case consists of a problem, a solution, and annotations on how the solution was derived.
Reuse - map solution from previous case to target problem, adapting if necessary.
Revise - test the new solution in the real world, and revise if necessary.
Retain - store the resulting experience as a new case.
Summary
ExcelicareCBR is a case-based reasoning (CBR) system that complements the Excelicare electronic medical record system. It allows domain experts (non-programmers) to author their own clinical decision support items.
Most CBR systems are prototypes, but are intended for commercialization. More of half of CBR systems address more than one task.
A combination of rule based reasoning (RBR) and CBR for an ICU. Pure RBR takes years to build a knowledge based, and CBR uses old cases to solve new cases. This system enhances a CBR system with an RBR system.
Clues
1. Sequence of activities in clinical pathway = generic clinical process
How CBR works:
Retrieval step: new problem is matched against previous cases in library
Domain knowledge: determines how similar and suitability case is to the previous one
Relevant solutions proposed
Revision of selected solution if needed before it is reused
New problem and solution are kept in case library for future use
Rule-based reasoning (RBR) can be very inflexible because
Knowledge base depends entirely on expert knowledge
It takes years to build that knowledge base, even for one domain
What if we could combine that with CBR, which can address those problems?
No need to maintain knowledge base for each domain
Can (in theory) automatically extend knowledge to different domains
2. A case C is a set of groups G
Hard things about CBR
Feature extraction from complex data formats like sensors, images, time series, and free text
Feature selection and weighting of those features
Library maintenance and case mining, especially in the beginning when there are a limited number of cases
Lack of automatic adaption strategies. Most are performed manually due to the complexity of medical domains, rapid changes in medical knowledge, large number of features, reliability and risk analysis
History Lesson
Internist (1974) was one of first clinical decision support systems, and used for internal medicine. Using rule-based reasoning, it could deduce a list of compatible disease states using a tree-structured databse that links diseases with symptoms. Internist was the basis for its successors, Quick Medical Reference (QMR) and CADUCEUS.
Mycin (1976) diagnosed microbial blood infections with if-then rules in a backward chaining reasoning strategy.
3. You can compare similarity between cases by aggregating each ordered instance pair. The weight w ensures that recent instances contribute more toward the final score than older ones.
Trends in CBR
68% of systems serve more than one purpose, up from 13% in 2003. CBR systems are also increasingly supporting more complex tasks and are combining purposes, like knowledge acquisition and classification.
Feature mining from multimedia data
Only Perner and Corchado have successfully commercialized
Some attempts at automatic and semi-automatic adaptation
k nearest neighbor is still most popular distance function, some attempts at fuzzy logic
System architecture: CBR system
CBR agent - searches for cases with simple domain key
CBR decision maker - decides the observations to be made and makes a decision
Performance monitor - archives certain rules of cases that were successfully solved
RBR module - taxonomy of rules with a forward chaining mechanism
4. Case authoring: A domain expert can design his own case representation by selecting individual data fields and map them onto case features. He can also put multiple goals for each feature.
Trends:
Integrating CBR with other AI methods, like statistical methods, fuzzy logic, and self-organizing maps
Automatic case-adaption will be key in the future. About half of the systems are already incorporating automatic adaptation
Two methods of measuring distance
Weighted Euclidean distance
Mahalanobis distance can also be used to compare the similarity of an unknown sample to a known one. It takes into account the correlations of the data and is scale-invariant
Future work
Indexing still slow, not scalable
Other similarity methods possible
Case maintenance
Time-dependent data
Patient data protection when retrieving cases
Right now, automatic adaption is the biggest weak point.
They should try it out on a real system and not just a simulation
They developed a rule-based clinical decision support system (CDSS) to prevent adverse drug events (ADEs), adopting computer interpretable guidelines (CIGs), all under a knowledge base (KB) structure. This hard due to lack of reliable knowledge about ADEs and poor IT ability to deliver appropriate knowledge to physicians.
Clues
Theory
Implementation
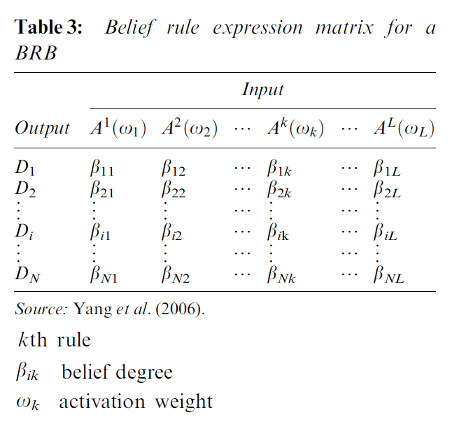
1. The knowledge model consists of rules, which are made up of
Conditions
Drug class and specific drugs
Labs
Diagnosis
Patient parameters
Effects - predicted outcome and recommendation for action
and these rules are applied by
Meta-rules - filtering mechanism that can "deactivate" rules in certain circumstances
Context - attributes that specify a local setting, like a hospital or target user
Statistics - filters rules for statistical significance and adjusts the KB to specific hospitals or clinics
Gaston is used for representing ADE rules
2. Knowledge conditions C are the building blocks to defining ADE signals. For example, a rule could look like:
Treatment with potassium
and no urinary retention
and 70
... may result in renal failure
lots and lots of metafilters
3. Rules are obtained by
association or decision tree induced rules - obtained by data mining
drug-drug interactions
literature
tacit knowledge
human factors and clinical procedure analysis
Standardization of knowledge is still a challenge. Interoperability is hard.
4. The CIG formalism or knowledge framework architecture consists of:
Knowledge base (KB) - source knowledge of ADE signals
KB instantiation and update mechanism - populates KB with ADE signals, and updates them with an automatic import function
Knowledge verification mechanism - verifies syntax of updates
KB contextualization mechanism - contextualized the ADE signal meta-data
Knowledge export mechanism - exports in various frameworks and standards
Inference engine - filters help eliminate alert fatigue, defines thresholds, customizes KBS output
Interface to external knowledge sources - may have to deal with issues of ownership of content, responsibility/accountability, maintenance and control
Interface to external healthcare systems and services - needs specification for external CPOE or EHR systems
External knowledge sources is complementary, but not comprehensive. Some ADEs can be missed.
The reasoning scheme works as follows:
Evaluation: computational cost of each step and the "correctness" of KB content
Future work
Major issues include:
Source knowledge: Granularity of binary lab values limited, perhaps can be solved with fuzzy logic. NLP may be required for clinical observations
Representing time dependent data
the relationship between falsity, negation, and lack of knowledge
Over-alerting and alert fatigue are major issues. Currently, the reasoning scheme filters excess ADE alerts with lots and lots and lots of meta-rules handling contextual parameters.
It is hard to represent uncertainty in medical knowledge, which exists in every clinical step. This paper tells you how to apply a rule-based inference methodology using an evidential reasoning approach (Rimer).
Rimer is different because it represents knowledge with belief rules, which are regular rules with an embedded belief degree. This belief rule-based methodology captures vagueness, incompleteness, and non-linear causal relationships.
It uses multiple attribute decision analysis (MADA) in its inference engine. Traditional approaches use a decision matrix, but this uses a belief decision matrix.
Belief rule matrix
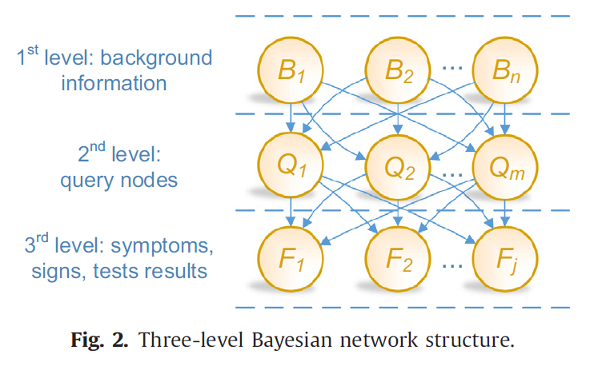
They are using a Bayesian Network (BN) to help diagnosis dementia. It is a semantic network-based system, which means it uses semantic relations between concepts in its inference engine. It uses a causal diagram, in which symptoms, signs, test results, and background information are probabilistically associated with random variables linked to each other. It also has a graphical interface, so a domain expert can easily access it. The random variables are derived from patient datasets, and built on a three-level generic BN structure. The probability distribution was estimated with a supervised learning algorithm, using patient data from 5 hospitals.
Title
BN structure: background info, disease, and symptoms/test results
James Spader likes comparing semantic-based similarity measures!
This paper tested 3 methods of measuring similarity by semantic approaches.
Definitions
Semantic similarity is the proximity of two concepts within a given ontology. The inverse of this is the distance between two concepts. Knowledge codified in ontologies can be the basis of semantic-similarity measures with the length of the path between two concepts or the weight of the edges of the path with information content.
Information-content strategy to computing semantic similarity is computing the frequency in which one terms appears with another.
The descendant distance (DD): the descendants of a given concept are used to weight the path links from one concept to another.
The term frequency (TF): the concepts term frequenct in a corpus weights the path edges within an ontology.
Results
None of the three metrics (cluster, DD, TF,)had a strong co-relation with the expert evaluations (gold standard). None of the semantic similarity measures even had a strong co-relation with each other. So we need to think before using distances as a proxy for semantic similarity.
James Spader likes a history of Internist and QMR!
Internist-1 and its successor, Quick Medical Reference (QMR) provide diagnostic assistance with internal medicine. Both rely on the Internist knowledge base. Whereas Internist functioned as a high-powered diagnostic "Oracle of Delphi" program, QMR is more of an information tool. QMR provides users with ways of reviewing and manipulating the diagnostic information in the knowledge base, and helps with generating hypotheses in complex patient cases.
Improvements
Internist
QMR
The knowledge base was built by Jack Myers and his team of 50 to 100 medical students. When they wanted to add a disease profile, they put in one to two weeks of full-time effort to examine textbooks, 50-100 primary literature articles, and compile it into a list of ~85 findings. This was subsequently reviewed by a more senior team. However, Internist did not allow users to have direct, immediate access to his information.
QMR used the Internist knowledge base. However, clinicians can click on button that displays the disease profile findings and links.
Doctors had to spend 30 to 75 minutes entering 50 to 180 positive and negative findings into Internist.
The QMR completer program allows users to quickly enter their findings. Think a rudimentary Google suggestions!
Internist was a "Greek oracle."
QMR has a case analysis on two modes. The first mode is for simple cases, and gives confirmation that a differential diagnosis has been reached. The second mode is for more complex cases. It allows the user to generate and rank hypotheses, pick the ones he likes, re-rank them, add new information, critique a diagnosis, and so on. It acts more as a consultant.
Diagnostic spreadsheet to show how groups of diseases and findings may co-occur
Expert consultant to analyze a diagnostic case
Nuts and bolts
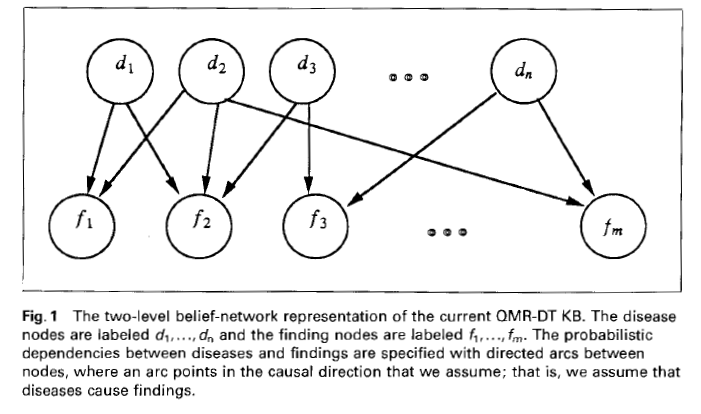
They made Quick Medical Reference, Decision Theoretic (QMR-DT), which is a decision-theoretic version of QMR. Decision theory uses probability theory and utility theory to choose among alternative courses of action. It is built on a a belief network, or Bayesian belief network, or causal probabilistic network, which are all graphical representations of probabilistic dependencies among variables.
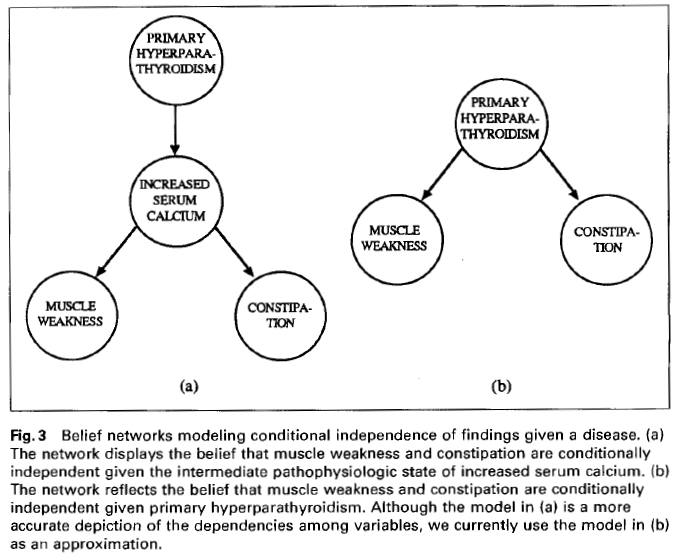
Belief network theory: the belief network is structured by a conditional-independence assumption.Belief network applications: In figure A, muscle weakness and constipation are independent. In B, muscle weakness and constipation are not independent, given primary hyperparathyroidism.
Final
Way over my head!
James Spader likes making a score for measuring diagnostic plans and management plans!
Usually people only evaluate CDSS on their diagnostic quality.
Greek oracle - predicting "correct" diagnosis or not
Relevance and comprehensiveness - ranking of diagnostic hypotheses to "gold standard"
Impact on user diagnosistic plans - did CDS positively affect diagnostic reasoning?
Purpose
Create an composite diagnostic quality score (DQS) and a management quality score (MQS). These measure changes in the diagnostic plan and changes in the management plan.
The quality of the diagnosis was based on the ratio of how well it explains the clinical findings (plausibility) and whether it is the most likely treatment in the setting (how treatable, how dangerous, prognosis, genetic implications).
The quality of the management plan was based on the ratio of the appropriateness in the clinical scenario (how much value it adds to reaching a conclusive diagnosis) and its impact (potential to cause further clinical harm) and cost-benefit ratio.
A aggregate list of unique diagnoses and management items were created with a two step procedure. First, a panel of doctors individually came up with diagnoses and management plans independently, and then they were combined. Secondly, each of the items were then ranked by the same panel, without knowing which colleague provided which suggestions. This served as the gold standard.
Diagnostic suggestions are in title case, while management suggestios are in upper case.
Further weights were provided by:
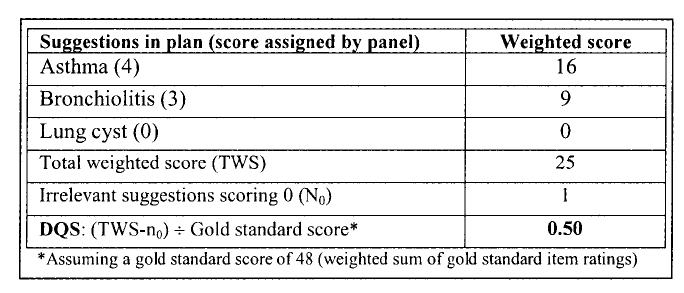
Relevance - One point was subtracted from the total weighted score (TWS) for each irrelevent suggestion
Comprehensiveness - The final DQS and MQS were calculated by dividing TWS by the gold standard score.
An example of the scoring procedure
Title
Reliability was scored by inter-rater reliability and validity was checked by a bunch of people looking over the scores and then checking that the medical students scored lower than the real doctors.
James Spader likes new and better ways of measuring how good a CDSS is!
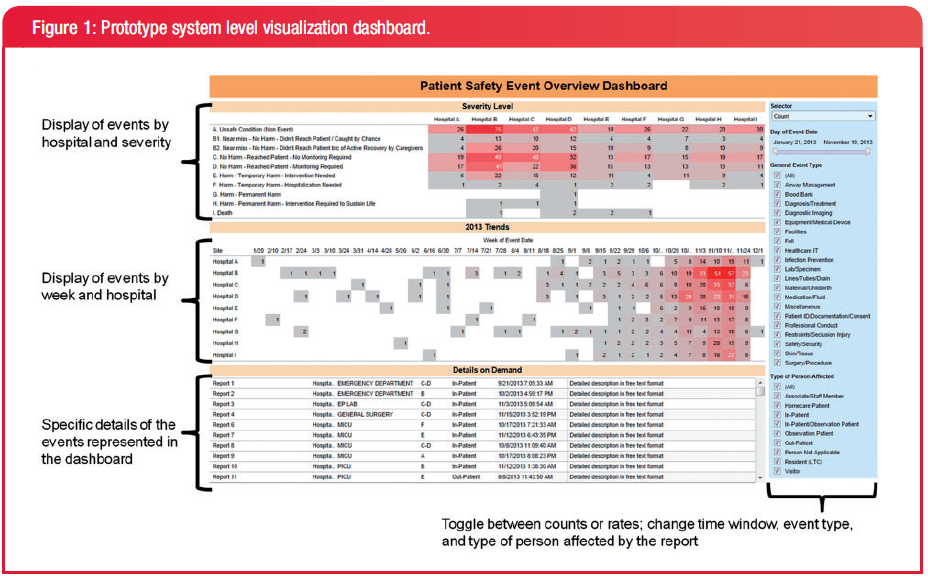
These guys made a dashboard for a patient safety event reporting system (PSRS), which records everything from "near misses" to serious safety events. They made it using Tableau!
There are two types of users:
System level users: concerned with high-level information about trends across hospitals. They want to improve awareness of event types reported, and compare from different time periods
Hospital level users: concerned with addressing specific events within their hospital. They want the current week data to 'take action' on events, and understand where those events are occurring.
Prototypes
System level prototype
This is the prototype for the system level users. They liked that the dashboard increased their awareness of events across different hospitals. They had no suggestions for improvement.
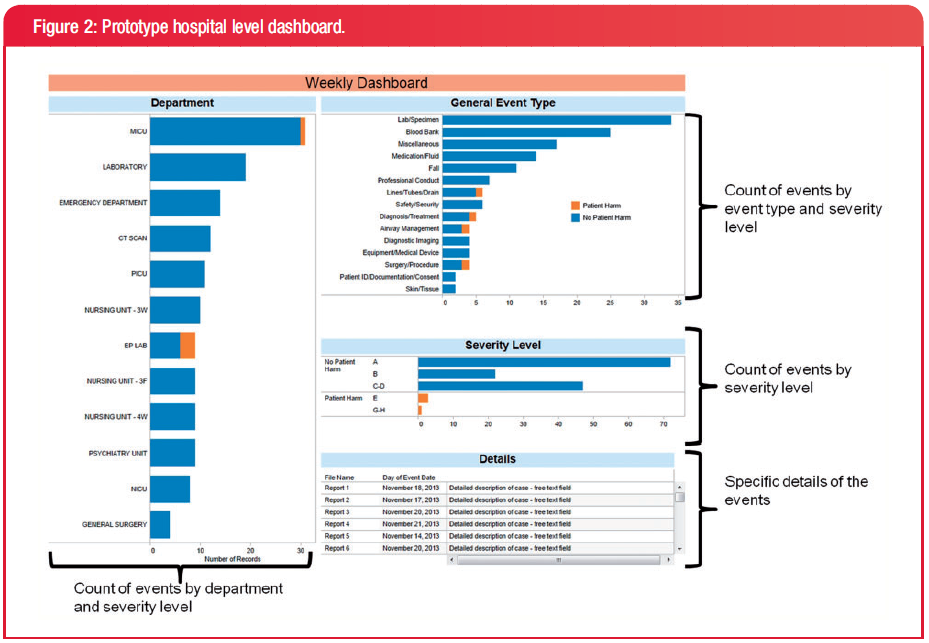
Hospital level prototype
This is the prototype for the hospital level users. They liked that they could quickly identify 'hot spots' of patient activity and could integrate the tool with their morning safety huddles and scheduled safety meetings. They suggested that a future dashboard should include the day/night of the event as well as who reported it and the status of the report.
Final version
Final version of the dashboard
James Spader likes reducing drug override rates using visualization methods!
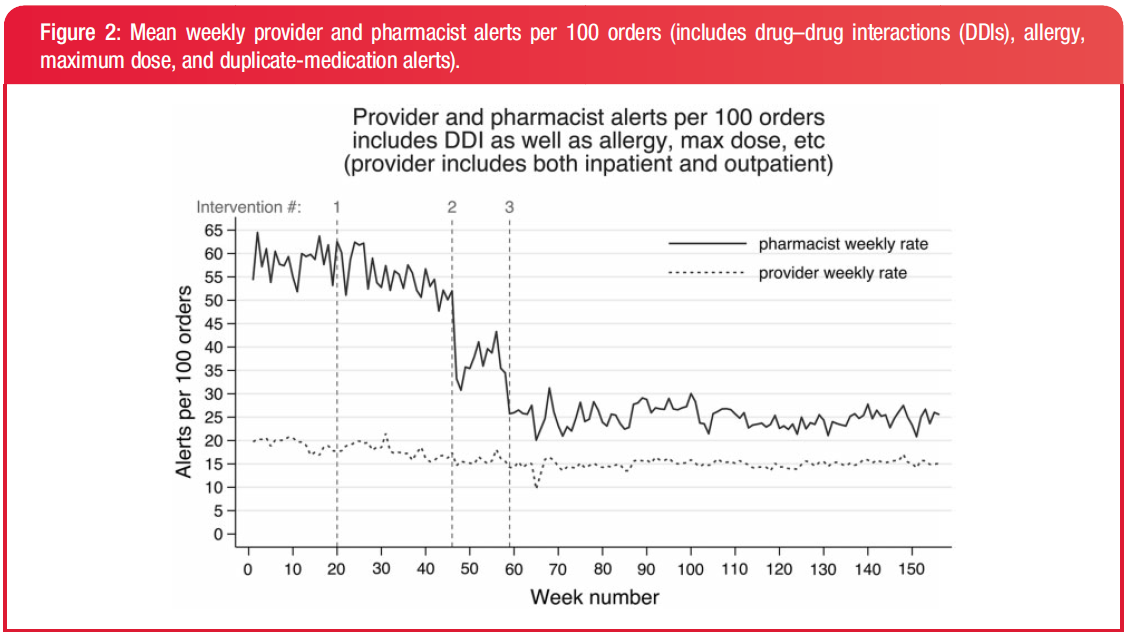
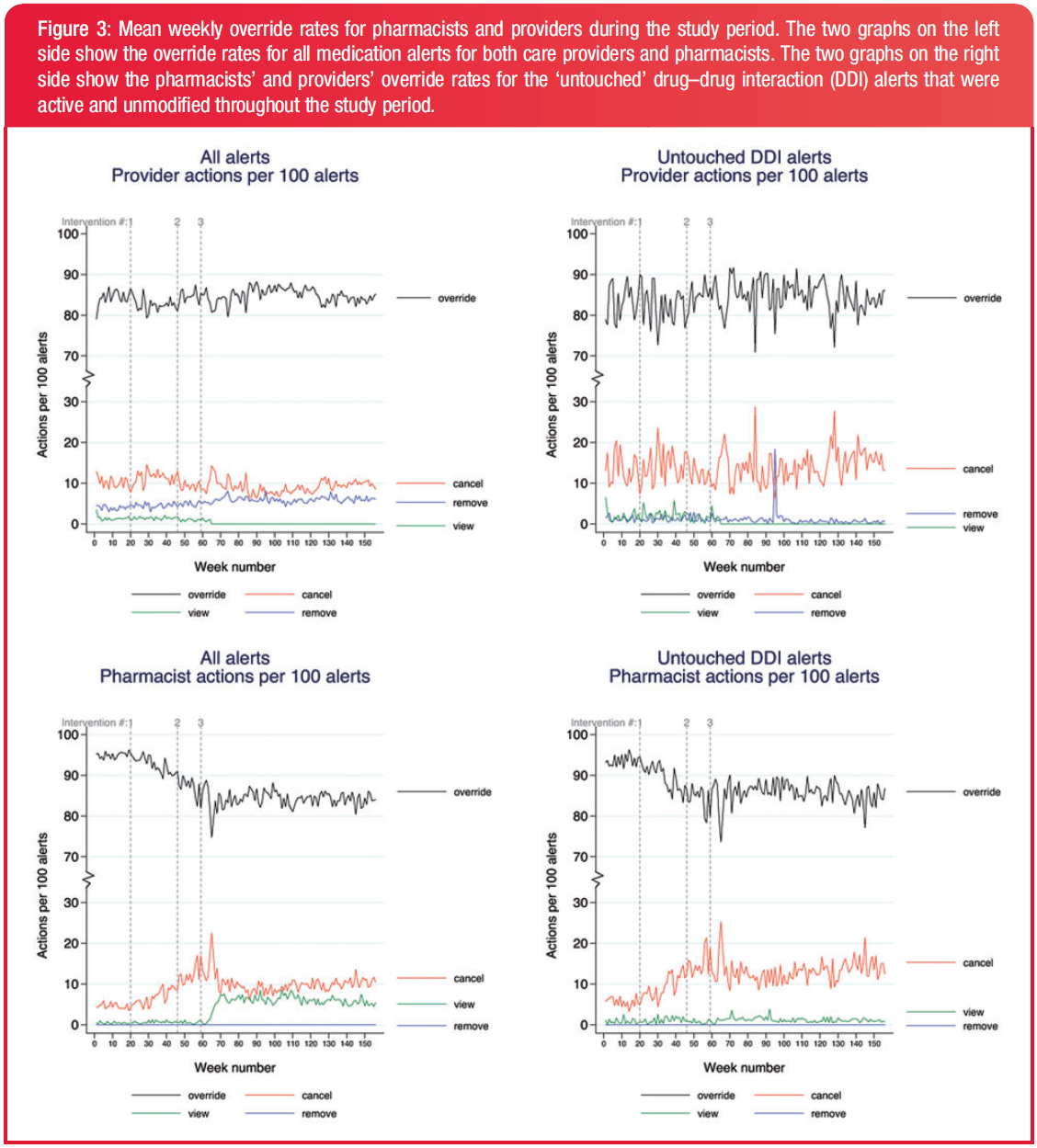
Many hospitals have all or a large percentage of available medication alert rules of all severities activated when they implement an EHR, all bu guaranteeing a system with high sensitivity and low specificity. This hospital used a a "self-service" visualization dashboard to bring down override rates from 93% to 85%.
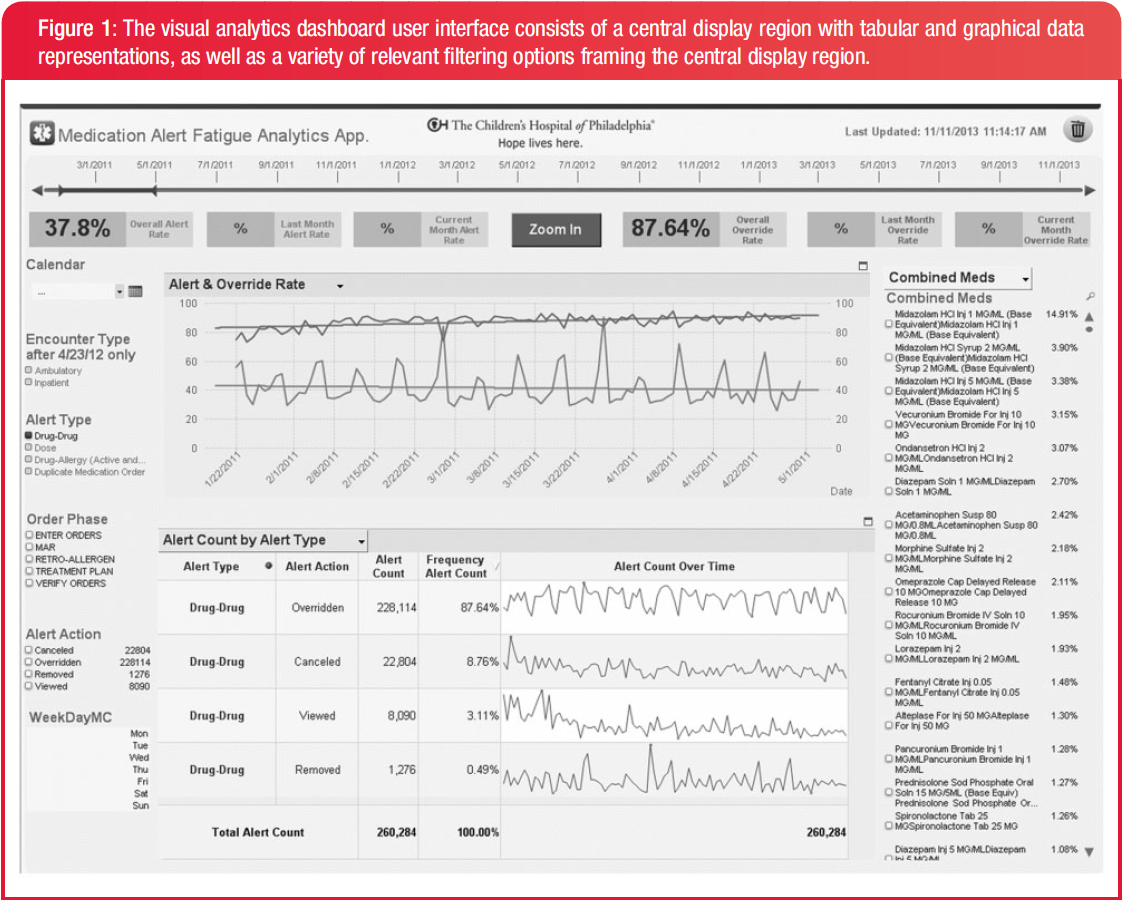
Dashboard
The dashboard that shows the workings of alerts. All allergy, maximum dose, duplicate medication, and drug-drug-interaction alerts are displayed in one window. Alerts can be overriden, canceled, removed, or viewed.
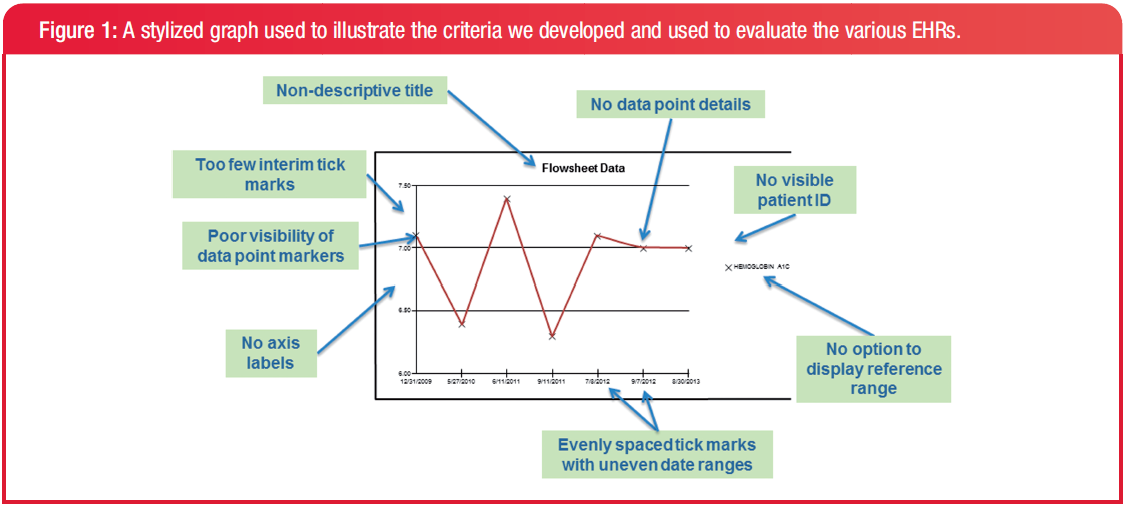
None of the EHRs met all 11 criteria. One EHR met 11/12 criteria, and 3 only met 5/12. In fact no EHR had a graph with y-axis labels that displayed the measured variable and the units of measure.
Half of new EHR contracts are with Epic, and half of the market is already Epic. But Epic is not seen "good," rather, only better than other inferior products. Literature also does not identify the inferity or superiority of Epic to other EHR systems.
A typical Epic installation costs from $250 million to $1.1 billion dollaroos, and implementation accounts from 2/3 to 3/5 of the total cost.
Advantages of an Epic monoculture
De facto data standards, similar user interfaces and formats, interoperability
Reduces need for training (like Microsoft monopoly)
Large and growing user group
Epic involvement with meaningful use guideline creation
Disadvantages of an Epic monoculture
Costs, 10-fold price difference between Epic and non-Epic installation
Harvard-Partners: $1.6 billion
Duke: $700 million
Sutters East Bay hospitals: $1 billion
Lockin in costs: Continuing costs for maintenance, development, customizations, training, and upgrades, as well as opprotunity costs from implementation interuptions
James Spader likes the impact of EHRs on ambulatory practices!
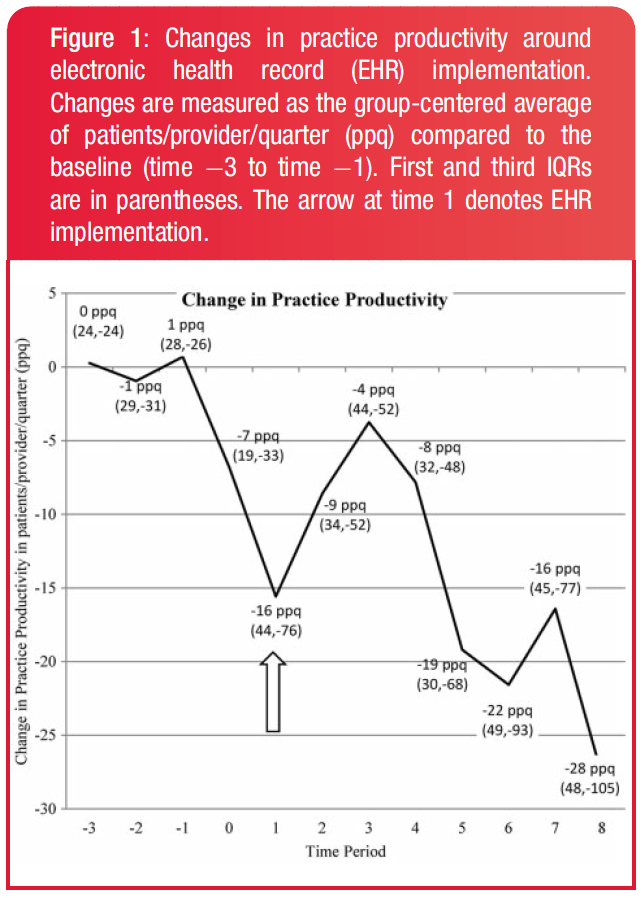
They tracked the number of patient visits (practice productivity) and reimbursement of 30 ambulatory practices for 2 years post-EHR implementation and compared to their pre-EHR baseline.
Background
Does EHR implementation decrease a practices revenue stream? Some claim that EHR implementation temporarily decreases practice productivity by 30–50%, but it returns to baseline within about 3 months. Some say it increases productivity. But they have 3 problems:
Some studies used proxy indicators of productivity instead of tracking the actual number of patient visits
Some studies have looked at the impact of EHR across an entire health system, so it is hard to apply to individual practices.
High-level financial measures such as return on investment or profits do not illustrate the financial dynamics
of ambulatory practices, such as the number of patients seen and the reimbursements from those visits
Results
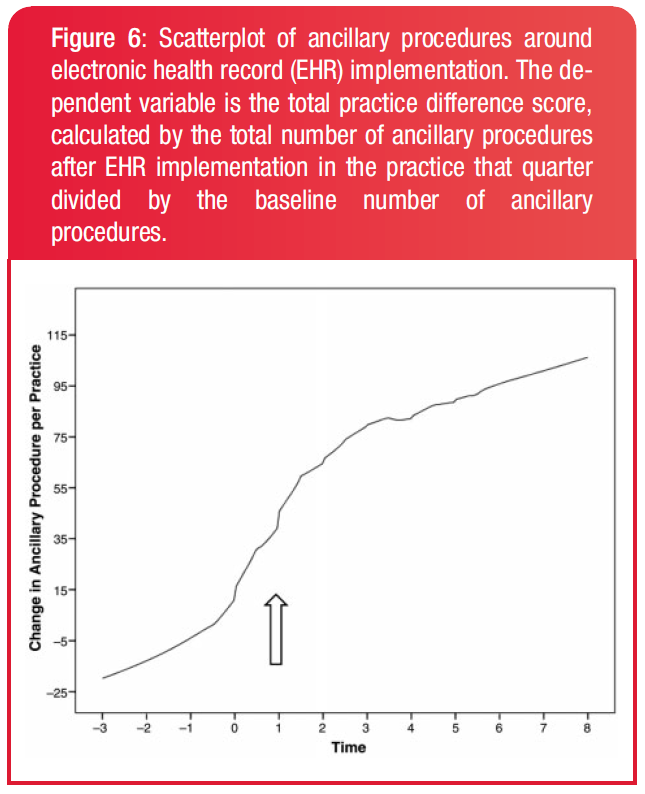
EHR implementation had a negative effect on patients per physician seen.However, practices hired more physicians, so it was not a recession.Whoa, but physicans were not upcoding, ie, claiming more per visit, because that is bad. Insurers were also not suddenly more generous. It was because they were billing more ancillary procedures.
Conclusion
EHR implementation increases reimbursements but reduces long-term practice productivity.
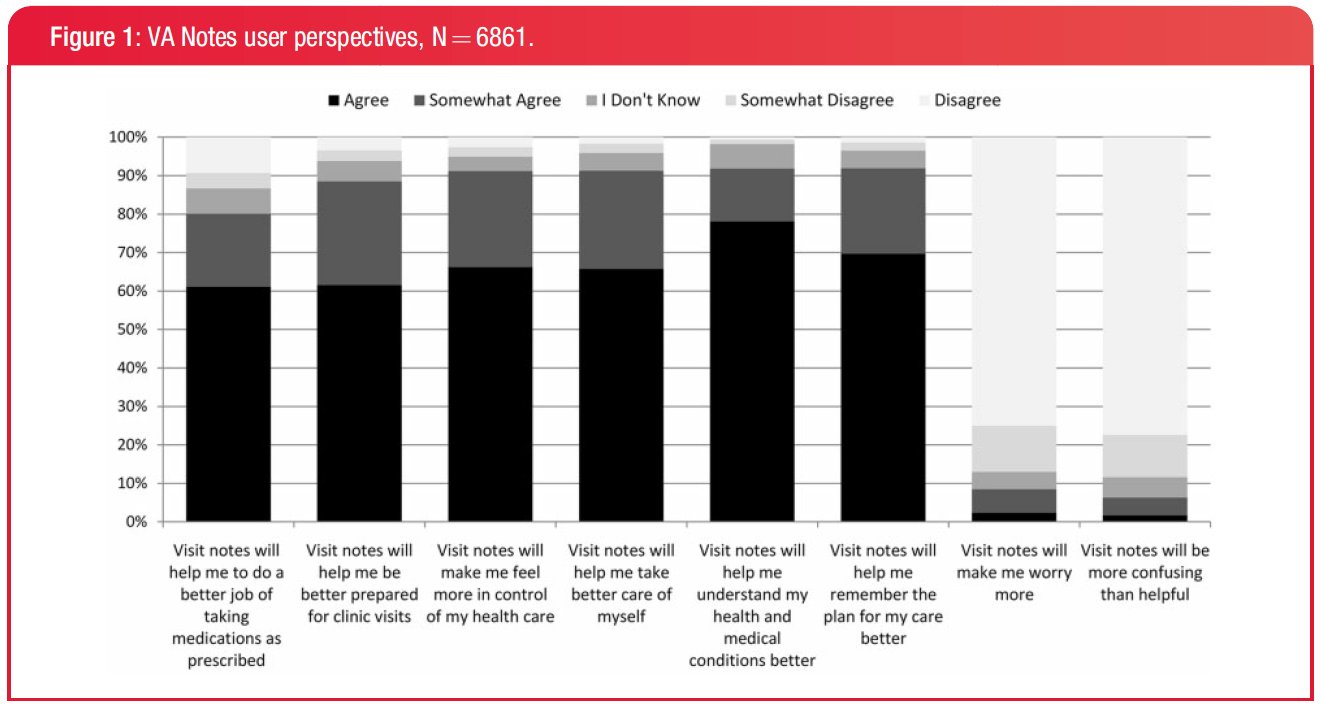
Stage 2 of meaningful use requires that patients be able to view their electronic health information. The VA implemented a personla health records (PHR) in 2010. By 2013, 33% of VA patients surveyed knew about it, and 23% viewed their notes at least once.
Motivations
26% said they viewed their PHR because they wanted to know more about their health
21% because they were curious
20% because they wanted to understand what their doctor said
The most common information sought were the notes written by a doctor during the visit (46%)
Title
Everyone likes PHRs!
Yup, people like accessing their information.
James Spader likes EHR adoption by small physician practices!
Small practices are less likely to have an EHR than large ones, and those EHRs tend to have fewer functionalities. People think the barriers are lack of money, lower ability to handle the productivty changes of an EHR, and lesser ability to choose a vendor. But is it true? 2677 physican practices answered.
Research question
The practice sizes were grouped into:
solo or 2 physicians
3 - 5
6 - 10
11+
In small and larger physican practices, what is the rate of:
Availability of EHR functionalities: Which key functionalities of an EHR represent the largest gaps in adoption between small and large practices?
Functionality use: Do physicians in small practices use key EHR functions at the same rate as physicians in large practices?
Barriers to adoption and the use of EHRs: What are the key barriers to adoption among physicians in small practices and how do they differ from the barriers faced by large practices?
Impact of the EHR on the practice and quality of patient care: Do physicians in small practices report a comparable experience in terms of the impact on clinical practice that is reported by physicians of larger practices
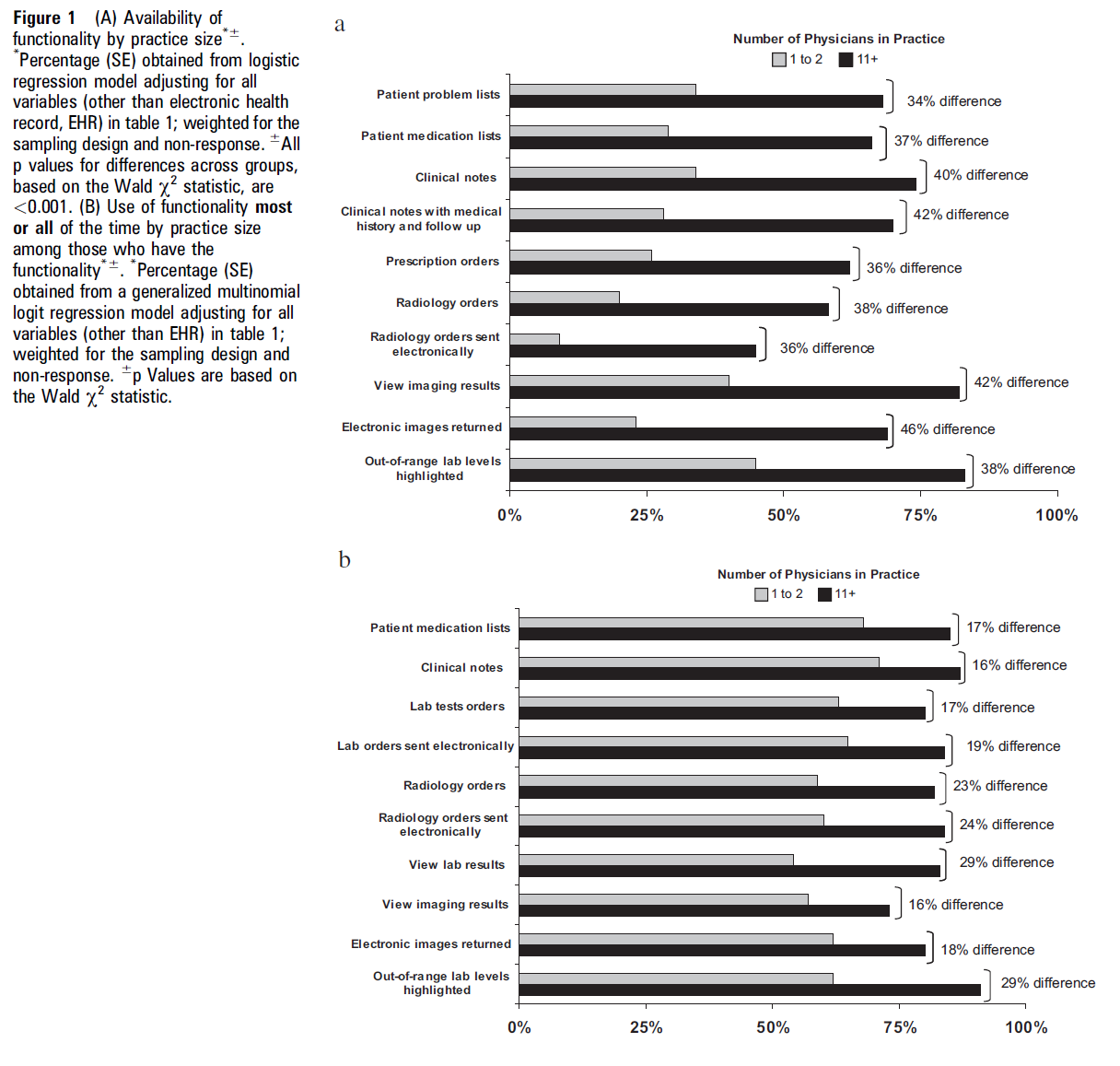
Results
13% of physicians in practices with 11+ reported a fully functional EHR, and 26% with a basic system
<2% of physicians in a solo or two-physician practice reported a fully function EHR, with 5% having a basic system
There was a 21-46% difference in the availability of each of the functionalities between the smallest and largest practices.
The largest gaps are access to radiology images (46%), radiology reports (42%), and clinical notes about followup (42%).
Physicians from small practices were more likely to report financial barriers. Interestingly, general resistance to EHRs and negatie productiveity concerns were not seen as barriers.
Both small and large physician practices equally benefited from the for metrics such as quality of clinical decisions, communication with patients and other providers, avoiding medication errors, and refills. Interestingly, there were moderate to large differences in things that required more advanced CDS functions, like being alterted to a critical lab value.
Conclusion
Physicians in small practices are less likely adopted EHRs, and their EHRs have less functions as well, particularly in ordering radiologic tests, having electronic clinical notes, and electronic prescribing. Maybe the EHRs sold to small practices are of lower quality?
The Health Information Technology for Economic and Clinical Health (HITECH) Act of 2009 as part of the American Recovery and Reinvestment Act (ARRA) made meaningful use: get an EMR, make sure that it is good, and we will give you money.
A basic EHR is a computerized system that has each of the following types of features:
patient demographic characteristics
physician notes
nursing assessments
patient problem lists
laboratory and radiology reports
diagnostic test results
computerized ordering (CPOE) for medications
A comprehensive EHR has all of the basic functions, and:
Physician notes
Nursing assessments
Advanced directives
Radiologic images
Diagnostic test images
Consultant reports
Laboratory tests
Radiologic tests
Consultant requests
Nursing orders
Clinical guidelines
Clinical reminders
Drug-allergy alerts
Drug-drug interaction alerts
Drug-laboratory interaction alerts
Drug-dose support
Meaningful use
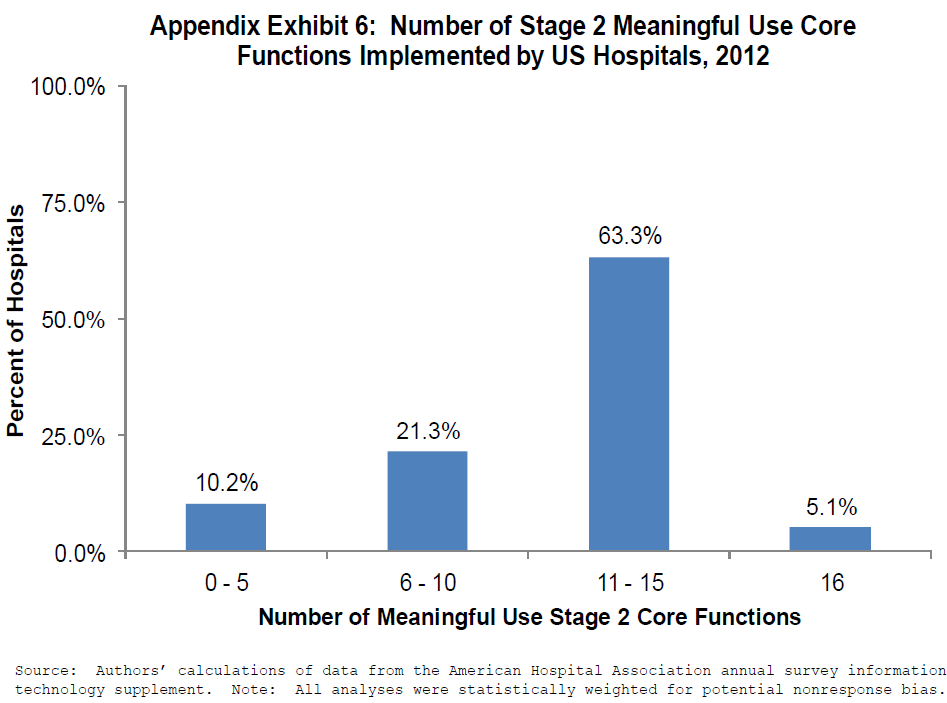
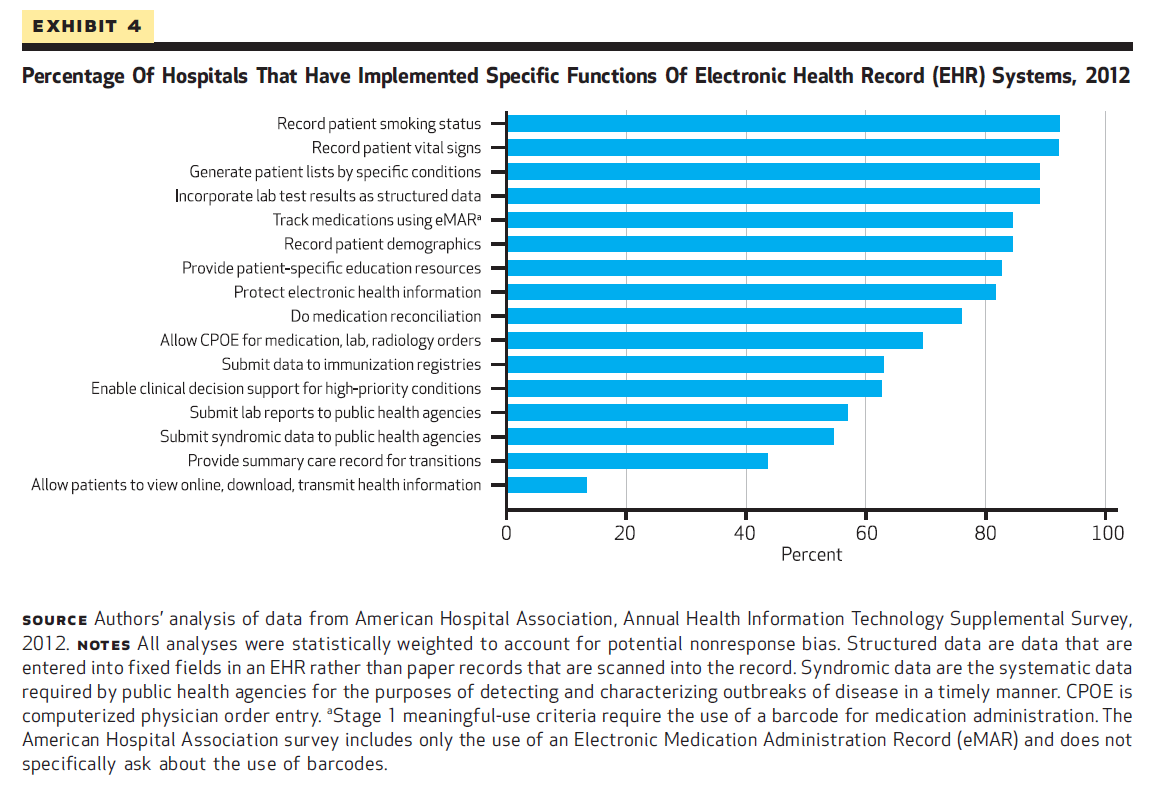
Meaningful use, an "escalator" designed to move hospitals toward higher quality care, are implemented in 3 stages. Hospitals that do not meat meaningful use criteria by their deadlines face financial penalties that increase over time. 42.2% of hospitals meet stage 1 meaningful use criteria, but only 5.1% meet stage 2 criteria.
Stage 1: began in 2011
Stage 2: criteria finalized in 2012
Stage 3: scheduled to go into effect in 2016
63% of hospitals implemented between 11-13 functions to meet stage 2. 21.3% meet 6-10 functions, and 10.3% have 5 or fewer functions.
42.2% of hospitals can meet all 14 core criteria of stage 1 meaningful use. But only 5.1% meet stage 2 criteria. The most common features are recording the patient smoking status and their vital signs.
Charts
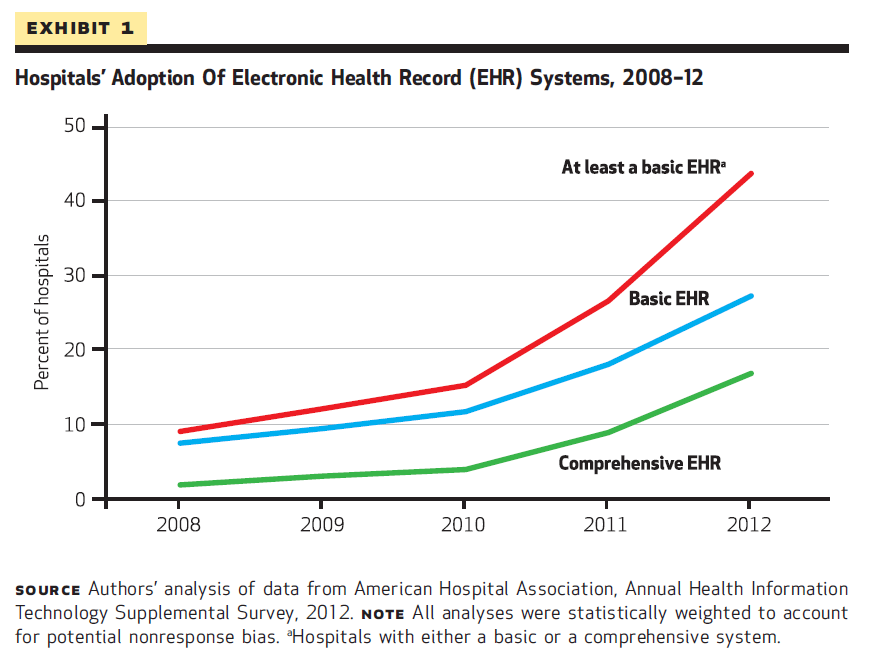
In 2012, 44 percent of hospitals report having a basic or comprehensive EHR system. That is nearly 3x higher than the figure in 2010.
Conclusion
3 major challenges:
More than half of hospitals do not meet stage 1 meaningful use
Only a small number of hospitals can meet stage 2 meaningful use
Rural and small hospitals are lagging behind their urban and large counterparts